- Solutions
-
-
Featured Solution
 Get more value from your existing SAP BW and SAP HANA investments with our SAP integrations.
Get more value from your existing SAP BW and SAP HANA investments with our SAP integrations.
-
-


Pyramid provides the fastest analytic solution for SAP HANA using SQL while still exposing all its deep analytic logic and functionality. Combined with Pyramid’s complete self-service analytics platform, it’s one of the strongest and most comprehensive analytical toolsets for SAP HANA in the market.
This blog is part 2 in a two-part series exploring Pyramid’s functional capabilities and certifications for SAP HANA.
Many SAP customers encounter issues trying to find a set of analytic tools that work directly on SAP HANA with modern self-service analytic capabilities—while exposing all the enterprise, server-based functionality required for security and governance (not to mention HANA’s superb querying speed). Few companies want to lose this functionality when implementing a BI tool with their HANA engine.
In short, customers want “Real self-service BI that works directly on SAP HANA.”
To recap from my previous post, HANA is a super-fast, in-memory, relational database that acts as both the specific storage mechanism for SAP’s ERP “S4HANA” as well as a generic database solution that enables data analysts to query large volumes of data in real-time. The in-memory computing engine allows HANA to process data stored in RAM as opposed to reading it from a disk.
Importantly, HANA has its own deep analytics capabilities deployed through “Calculation Views”—which are designed to expose powerful business logic and analytical layer that goes well beyond a simple database.
In my last post, I examined how Pyramid handles hierarchies, data formats (including currencies and unit conversions), and calculated attributes and measures—crucial capabilities that underpin the SAP HANA certification. In this post, we’ll take a closer look at parameters and variables, hyperlinks, and more.
The ability to dynamically query different subsets of data, amongst many other things, is a critical capability in HANA. Consequently, HANA provides parameters and variables to inject settings at run time to change the way queries and logic are executed—including “pre-filtering,” calculated values, and time-dependent hierarchies.
This optimizes query performance and analytic capabilities in several ways. First, it facilitates query optimization by running on a reduced subset of data. Second, it provides a method of dynamically altering the query by changing hierarchies, logic, and calculations and controlling different snapshots of the data to be queried.
Many third-party tools can handle and pass parameters to SAP HANA. However, they can often only pass a single set of variables per data model or pre-report. Others cannot handle the wide variety of functionality exposed through SAP parameters and variables at all (like Excel!). And for those that do handle them, a separate connection to the data model or session is required each time the variable is changed, such as when the variable needs to be changed for multiple types, for multiple users, or in multiple venues. This inflexibility defeats the purpose of having variables and parameters in the first place—and heavily blunts their impact on the reporting process.
Pyramid provides a comprehensive approach for HANA parameters and variables. It facilitates the use of these items for multiple users and multiple models in multiple venues on the same or multiple reports—within the same masterful construct. This means users can orchestrate multiple permutations of how to use parameters and variables so that each time a different query needs to be run, different parameters can be passed to the query by-user, by-report, per-session, or any combination thereof.
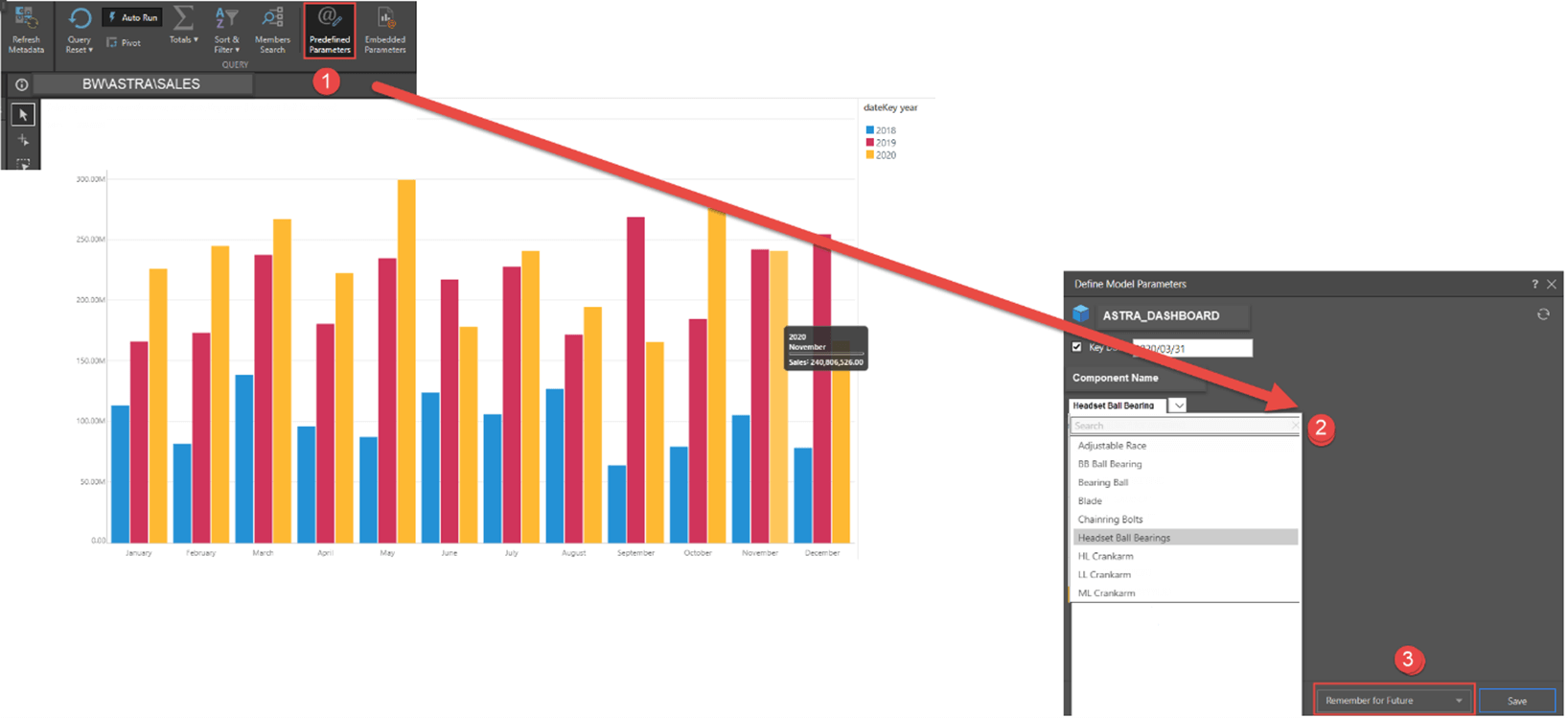
In this Monthly Component Report, a component—Headset Ball Bearings—is selected in Pyramid using SAP HANA’s variables. The selection used by this report is “remembered” and will be used automatically the next time this user accesses the report.
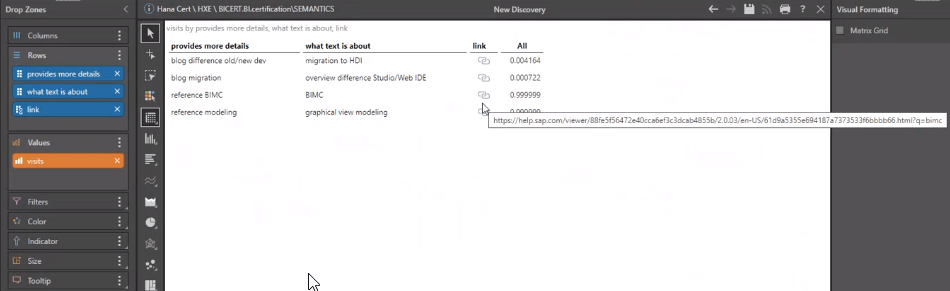
HANA has a built-in feature that produces specialized hyperlink hierarchies. Pyramid users can take full advantage of this built-in feature when connecting to their HANA environment. It allows users to click on the contents of the cell and be automatically transferred to the address embedded in the hyperlink.
In this HANA example, the link column exists in HANA, containing a different hyperlink for each row of data. The corresponding URL can be accessed by simply clicking on the cell.
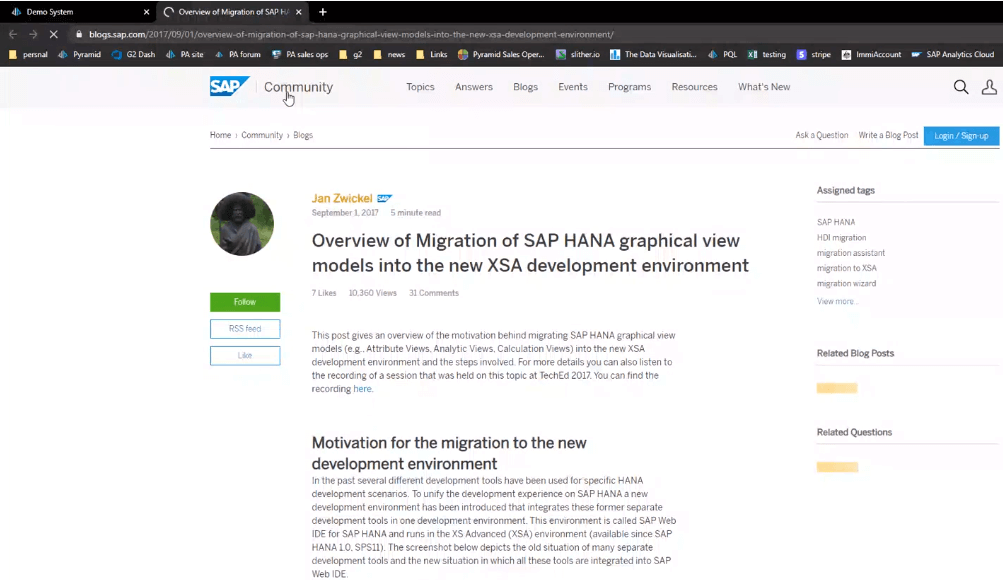
And the user is immediately transferred to the web page.
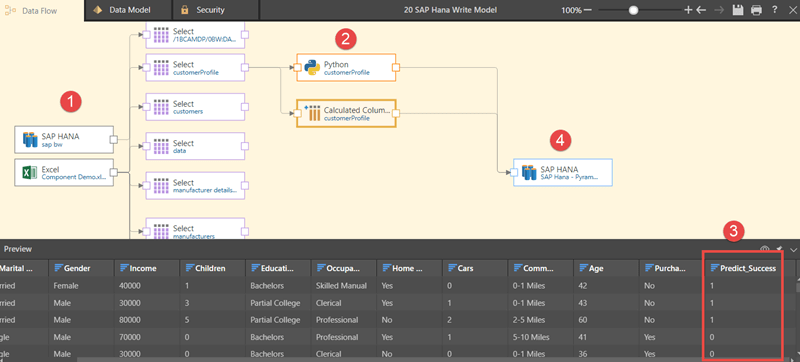
Most BI tools can read data from multiple data sources but can only write data into their own proprietary data layer. (This capability is often used as the backdoor “hack” needed to facilitate user-driven analytics since the same tools cannot operate directly on HANA). Pyramid, however, can read and write data to multiple database engines, including HANA. This unique ability means the application can be used to build data models and mashups, with the resultant data being written back into SAP HANA.
In this data model, the SAP HANA database is accessed as a source. Various SAP HANA tables are selected, data is mashed together with an Excel source, a Python machine learning script is applied, and most importantly, the resultant data sets—using all the complex machine learning scripts—are stored on SAP HANA.
The Python script is used to predict the loan status for the next month. Existing data fields are used as inputs into the Python script detailing loan amount, interest rate, previous defaults, net monthly income, et cetera, producing a “Predict Success” column where a value of 0 predicts a successful collection of the monthly loan repayment and a value of 1 predicts an unsuccessful collection.
Pyramid can create a dashboard consisting of multiple visualizations, each using its own data connection, where no ingestion of data and subsequent merging is required. This means Pyramid users can take advantage of dashboards or publications consisting of one or more HANA Calculation Views—which can each be independently seeded with different parameters and variables.
This dashboard contains three different visualizations (one from BW and two from HANA), each with different variables selected from their respective pop-up parameter screens.
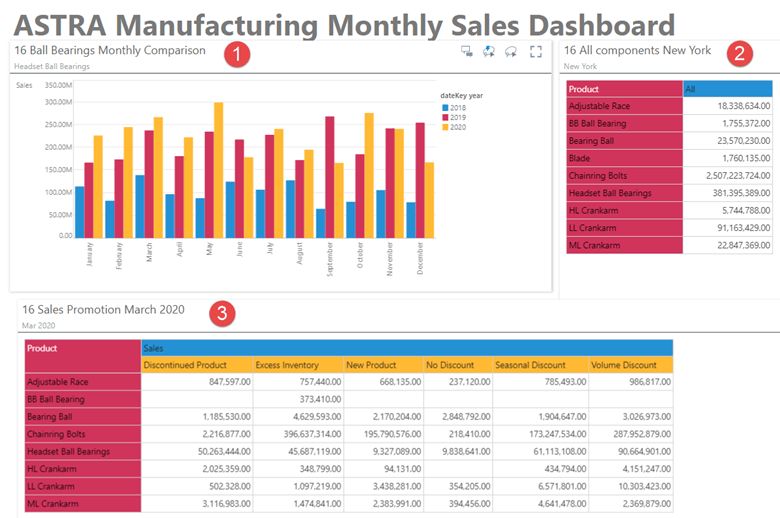
Pyramid enables total flexibility where the user can dynamically select multiple factories, components, or months using the same data model. The user does not need to worry about creating different data models and reloading the data for every analysis. In addition, Pyramid can automatically supply a different parameter for each branch manager to view his branch, also using the same data model. Pyramid also has optional functionality to remember the last parameters selected and defaults to them for future analysis.
SAP HANA allows measures and hierarchies to be organized into folders for easier management and access to model content. These features have been available in Pyramid since its inception and are an intrinsic component of Pyramid’s user-friendly interface.
Pyramid ensures that hidden data that has been defined as restricted in HANA is not exposed to end-users.
Pyramid enables the use of client session flags utilized by SAP HANA. This offers customized analytical experiences as defined by the HANA engineers.
The query language setting can be set for a given query to govern the language of the mode’s metadata and query results in a specific Discover report. This allows customers to show the same report in multiple languages—appropriate for each user on the system. Once set, the setting will drive the report and its subsequent usage in the platform.
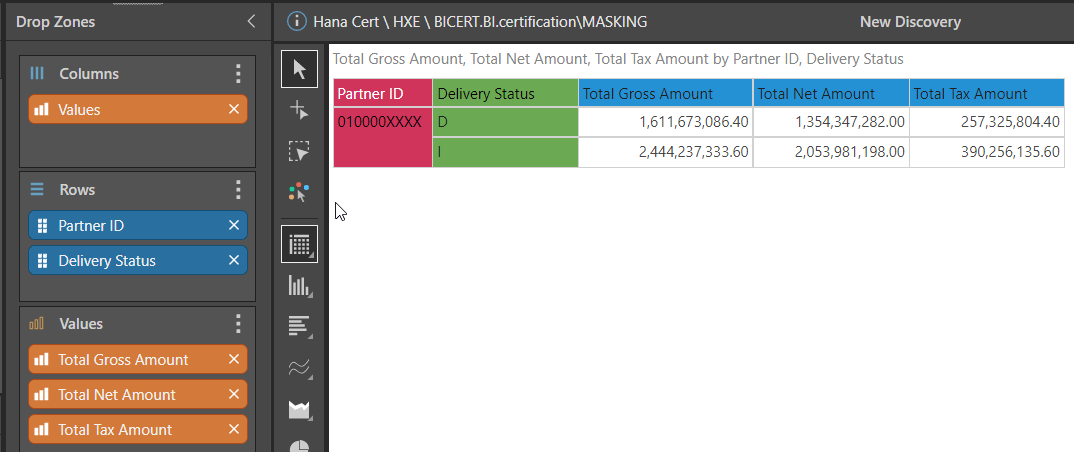
Pyramid provides support for SAP HANA’s ability to hide values in a visualization based on a user’s role.
In this example, the last four characters of the Partner ID have been masked in HANA. Pyramid mirrors this perfectly by masking the last four characters of Partner ID for all reports.
Pyramid offers SAP HANA customers the unparalleled ability to retain SAP HANA’s advanced analytic capabilities while providing the fastest querying solution using SQL. By performing direct queries on SAP HANA using SQL, Pyramid’s intrinsic MDX-like capabilities ensure both complete analytic functionality and speed with all the requisite security and governance. The richness and maturity of Pyramid’s self-service functionality overshadow SAP’s native BI offerings.
Many third-party self-service BI tools lack close integration with HANA with weak or limited support of the core functionality of HANA’s analytic functions. As such, they tend to encourage users to export their raw data out of HANA and reimport it into their native data stacks to gain better analytical functionality. The duplication of data runs contrary to the entire concept of using HANA in the first place and ultimately deleverages the investments in HANA and possibly the SAP ERP itself.
Pyramid achieved SAP HANA certification, not only ensuring compliance with the mandatory requirements but also including all the business-critical optional requirements, offering SAP HANA customers one of the strongest and most comprehensive analytical toolsets for SAP HANA in the market.
This concludes our two-part series on Pyramid’s SAP HANA functionality. For more information on Pyramid’s deep SAP support, visit https://www.pyramidanalytics.com/integrations/sap/.

How-To
SAP is essential enterprise software. Your organization has made significant investments in SAP. You've tailored…

How-To
Pyramid’s built-in multi-factor authentication (MFA) option adds a rock-solid layer of security to your BI…

How-To
Administrators occasionally need to check complicated settings and security structures for users. Sometimes the easiest…

How-To
Pyramid lets users customize and personalize the labels of value metrics and hierarchies for a…

How-To
Static data format masks, used to format values in analytics) is a standard feature in…

How-To
Pyramid lets users display multiple value metrics in a single report, each with its own…

How-To
Pyramid’s persistent color feature maintains the same color in all visualizations for selected data elements,…

How-To
Pyramid offers flexible, intuitive security for parent-child hierarchies, providing role-based control over how members are viewed…

How-To
Pyramid excels in its’ native support for parent-child hierarchies, automatically generating hierarchical structures and providing fluid,…